A content classifier in Actifile identifies files containing specified text patterns.

What types of content can I detect?
Let’s break down each of the existing options.
Contains any word
Flags files containing at least one of the given words.
Use cases
- Identify contracts or legal documents containing terms like “agreement,” “liability,” “warranty,” or “confidential.”
- Detect files containing the names of your company’s senior executives to secure sensitive communication.
- Protect your organization’s intellectual property by flagging files with terms like “design blueprint,” “patent application,” or “trade secret”
- Detect files containing key client names or terms, such as “Acme Corp,” “Customer ABC,” or specific product names used by clients.
Contains exact phrase
Flags files containing a specified phrase.
Use cases
- Identify files mentioning a specific project.
- Identify confidential documents by searching for phrases like “internal use only”.
Does not contain phrase
Flags files that miss a specified phrase.
Use cases
- Identify documents that lack mandatory language, for example, “HIPAA Compliance Notice” in healthcare documents.
Matches regex
Flags files that contain text matching a specified regular expression pattern, like emails, employee IDs, or bank account numbers.
Use cases
- Detect files containing unique employee IDs like
HR-US-1234for internal HR compliance.
- Locate documents storing software license keys or serial numbers.
Does not match regex
Flags files that missing text that matches a specified regular expression pattern.
Use cases
- Identify invoices missing a properly formatted invoice number (e.g.,
INV-123456).
Flag files that lack a version number, such as Version: 1.0.
Full name
Flags files containing the conbination of first name and last name.
Use cases
- Detect customer or employee names in documents.
Configurations
This section outlines the configurations available when setting up a content classifier. For detailed instructions on creating or editing a classifier, click here.
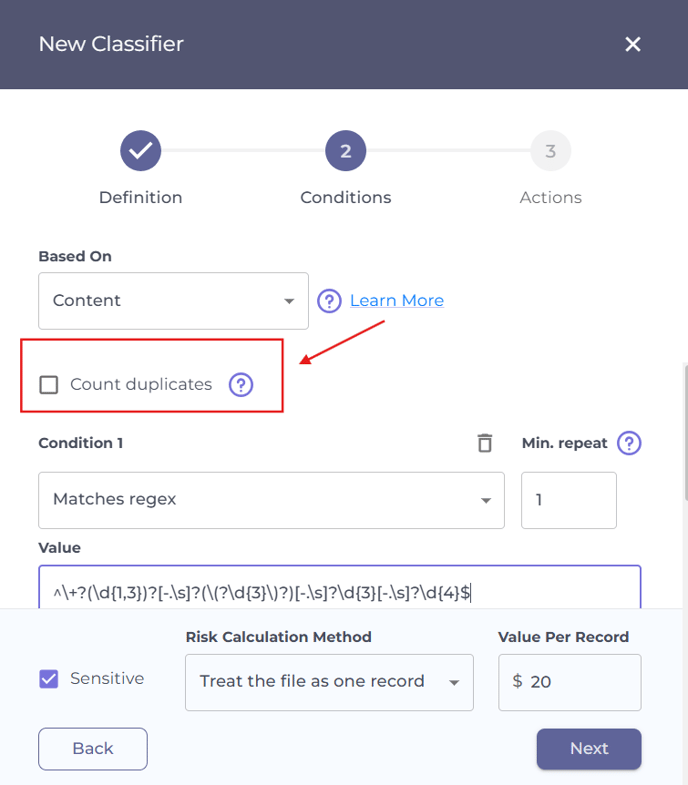
Count duplicates
If the Count duplicates box is unchecked, the agent counts only one occurrence of the specified content and ignores duplicates.
Example 1
- Condition for classification: a regular expression matching a phone number.
- Scenario: a file contains ten phone numbers, with three of them identical.
- Count duplicates: unchecked.
- Value per record: $20.
- Calculation: Duplicates are not taken into account. 10 occurrences – 2 duplicates = 8 records.
- Total risk value of the file: 8 records × $20 = $160.
Example 2
- Condition for classification: a regular expression matching a phone number.
- Scenario: a file contains ten phone numbers, with three of them being identical.
- Count duplicates: checked.
- Value per record: $20.
- Calculation: all occurrences are taken into account, resulting in 10 records.
- Total risk value of the file: 10 records × $20 = $200.
Minimum repeat
You can set a minimum repeat value to determine how many occurrences of the specified content are needed to flag a file as sensitive.
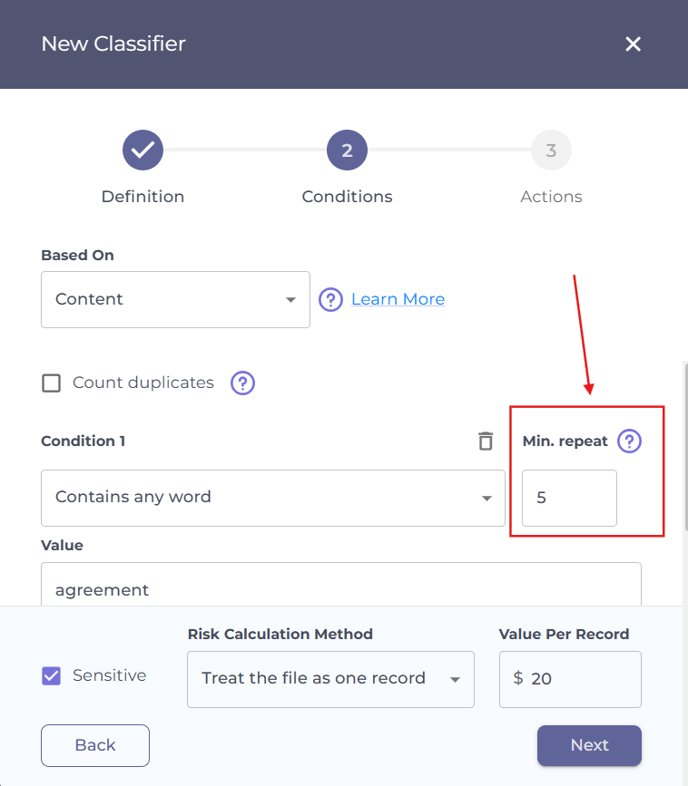
Example 1
- Scenario: A file contains four occurrences of the word “agreement.”
- Minimum repeat: 5.
- Count duplicates: either checked or unchecked.
- Value per record: $20.
- Calculation: 4 occurrences < 5 (min repeat). The file is not marked as sensitive, and no records are created.
- Total risk value of the file: 0.
Example 2
- Scenario: A file contains 12 occurrences of the word “agreement.”
- Minimum repeat: 5.
- Count duplicates: unchecked.
- Value per record: $20.
- Calculation: the file contains only one unique value (“agreement”), regardless of the number of occurrences. 1 < 5 (min repeat); therefore, the file is not marked as sensitive, and no records are created.
- Total risk value of the file: 0.
Example 3
- Scenario: A file contains 12 occurrences of the word “agreement.”
- Minimum repeat: 5.
- Count duplicates: checked.
- Value per record: $20.
- Calculation: 12 occurrences > 5 (min repeat). The file is marked as sensitive, and 12 records are created.
- Total risk value of the file: 12 records × $20 = $240.
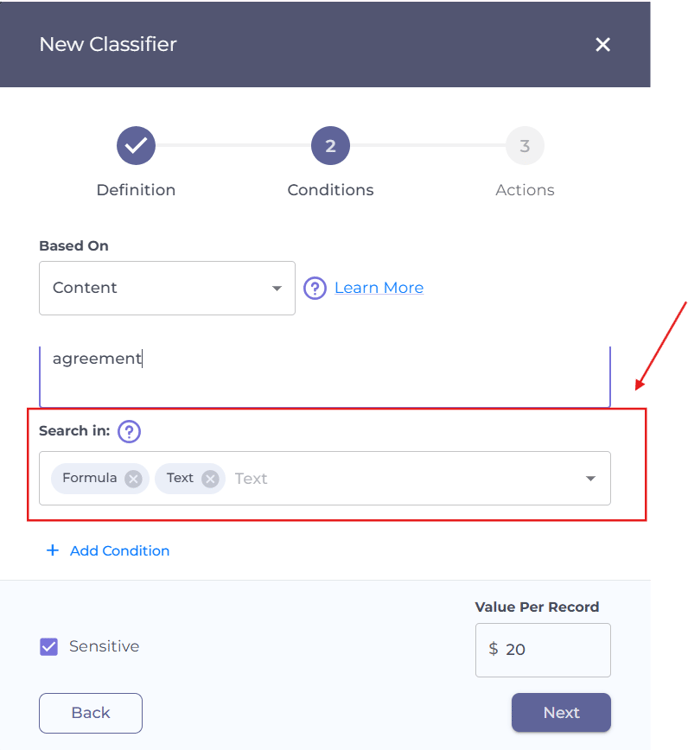
Search scope
By default, content classifiers scan only text. If you’d like to extend the search to include Excel formulas, you can configure the classifier to search within formulas, or in both formulas and text.
Note: Formula searches are supported exclusively for Excel files.
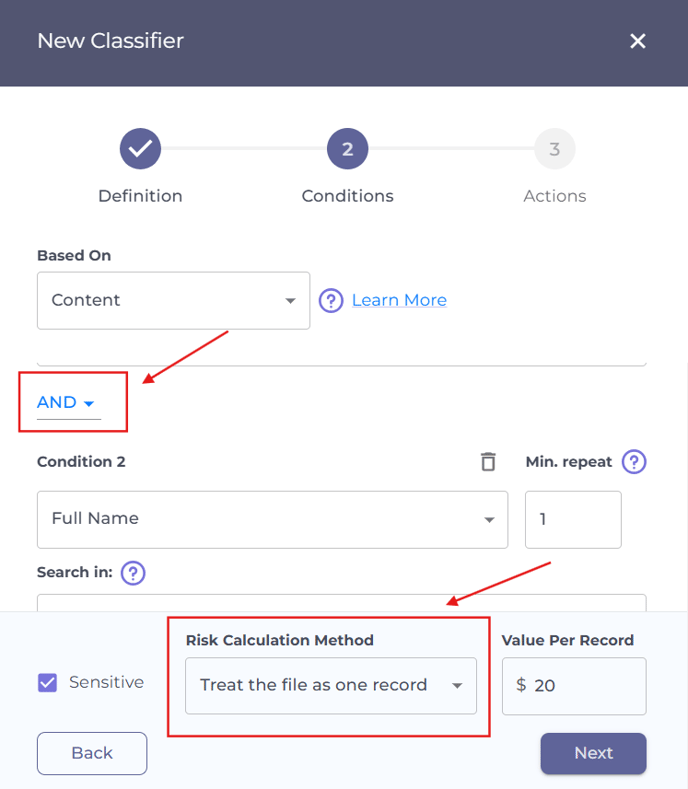
Risk calculation method
You can combine multiple conditions within your classifier by clicking Add Condition.
Each group can be configured with AND or OR relations:
- AND: The file must satisfy all conditions in the group to be flagged as sensitive.
- OR: The file will be flagged if it satisfies any condition in the group.
You can set the risk calculation method to the entire file or one of the conditions.
Example 1
- Scenario: A file contains three phone numbers and one full name and is therefore marked as sensitive.
- Count duplicates: checked.
- Value per record: $20.
- Risk calculation method: Condition 1.
- Calculation: Only the phone number condition is taken into account. With the count duplicates option checked, all three occurrences will be counted, resulting in three records.
- Total risk value of the file: 3 records × $20 = $60.
Example 2
- Scenario: A file contains three phone numbers and one full name and is therefore marked as sensitive.
- Count duplicates: either checked or unchecked.
- Value per record: $20.
- Risk calculation method: Treat the file as one record.
- Calculation: None of the individual conditions is taken into account. Since the file meets the classifier’s criteria, it will be treated as a single record.
- Total risk value of the file: 1 record × $20 = $20.